Javascript es un lenguaje de programación web ligero que es usado normalmente para elementos de experiencia de usuario del site.
En otras palabras:
«JavaScript es un lenguaje de programación que se utiliza principalmente para crear páginas web dinámicas. Una página web dinámica es aquella que incorpora efectos como texto que aparece y desaparece, animaciones, acciones que se activan al pulsar botones y ventanas con mensajes de aviso al usuario.»
Fuente: https://uniwebsidad.com/libros/javascript/capitulo-1
Las librerías de Javascript más populares son:
- Angular
- React
¿Por qué Javascript es importante en SEO?
Para los buscadores es más fácil leer una web escrita con html puro que aquellas que usan Javascript.
Javascript requiere un paso adicional en el proceso de indexación y rastreo de una web. Esto significa que requiere una renderización aparte.
Este video del canal Google Search Central, Martin Splitt da algunos consejos sobre Javascript y SEO para asegurarnos de que nuestro contenido en JS es indexable por el robot de Google.
???? Para saber más: Google – Understand the Javascript SEO basics
Cómo identificar webs con alto contenido en JavaScript
Para un analista SEO, es importante reconocer sitios que usan demasiado Javascript y descubrir si los enlaces están incluidos en contenido que depende de JavaScript para cargarse.
Para identificar contenido incluido en Javascript puedes:
- Usar la extensión Chrome Developer Tools para desactivar Javascript en la página.
- Comparar el DOM (la versión renderizada de la web que incluye Javascript) con el código fuente (el html puro de la página).
- Usar Google Mobile Friendly Test. Esta herramienta mostrará tanto el html renderizado de la web como una visión de cómo Google ve nuestro contenido. Esta herramienta también da información sobre recursos de la página que no pueden ser cargados y alertas de problemas con Javascript.
- Usar la «URL Inspection Tool» de Google Search Console. Al testear una URLs, GSC mostrará la versión renderizada de HTML de la URL que podemos comparar con el código fuente para observar diferencias producidas por Javascript. Esta herramienta también muestra una captura de pantalla como ejemplo de cómo Google ha renderizado la URL.
???? Recuerda que para analizar una web que se basa en Javascript tendrás que cambiar tu configuración de rastreo en Screaming Frog activando la opción de Javascript.
Puede que sea interesante hacer un rastreo de la web activando esta opción y otro con la opción desactivada para comprobar diferencias.

¿Cómo procesa y lee Google Javascript en una web?
Este diagrama de Google Search Central explica los pasos que sigue Google al procesar una web con Javascript.
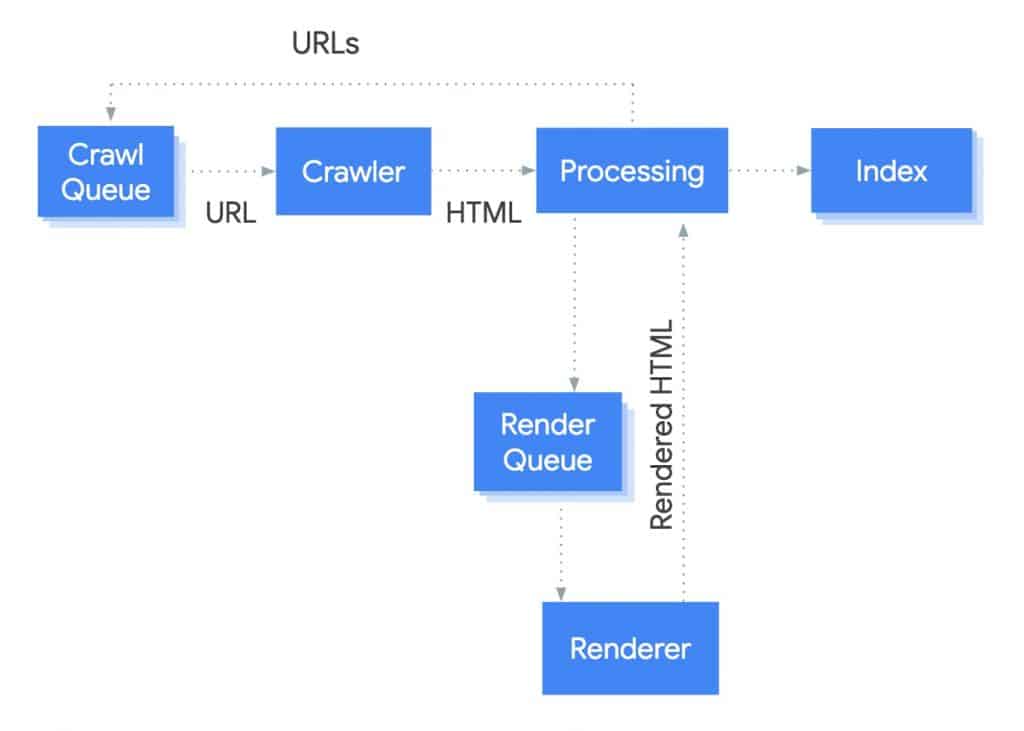
Hay 3 pasos principales en el proceso:
- Crawler o Rastreo: el proceso por el cual Google visita la web y lee el código y los enlaces contenidos en ella.
- Rendering o Renderizado: el proceso en el que Googlebot recupera el código de la web, ejecuta el código y analiza el contenido para entender el diseño y formato de tu web.
- Indexing o Indexación: el proceso por el que Google añade tu web a su listado una vez rastreada.
Y este es el camino que sigue en una página con Javascript:
- Crawler: Googlebot toma la URL de una página de la «Crawl Queue» y la sigue siempre que no se encuentre bloqueada. Google realizará un «parsing» que significa extraer los datos e información que le interesa de la web.
El contenido HTML que Googlebot encuentre después de realizar el parsing puede ser ya indexado (tercer paso).
En este primer paso, cualquier nuevo link en forma de URL que Googlebot encuentre será enviado a la cola «crawl queue» para seguir el mismo proceso. - Processing and rendering: en este segundo paso, Google procesará el Javascript.
Google sitúa esta página con Javascript en una cola de renderización o «render queue» donde esperará su turno a ser procesada.
Una vez Google realice el renderizado de Javascript, descubrirá nuevos links (URLs) que enviará a la cola de rastreo «crawl queue» para empezar el proceso de nuevo.
El nuevo contenido descubierto por el renderizado de Javascript pasará al tercer paso y será indexado. - Indexing: en este último paso, el contenido descubierto, ya sea del código HTML o mediante Javascript, se añadido al index de Google.
Cuando alguien busca por una keyword específica por la que la web rankea, la página aparecerá con el contenido disponible para el usuario.
¿Cómo indexa Google el contenido en Javascript?
Google rastrea el contenido en Javascript mediante lo que se demonina la segunda ola de indexación. En una primera ola, Google accede a la URL y obtiene el HTML. En una segunda ola, Google accede a la URL de nuevo y ejecuta el contenido JS para rastrearlo e indexarlo.
¿Cuáles son los retos de Javascript para SEO?
Estos son los desafíos o problemas que puede pasar Javascript en una web:
- Google (u otros buscadores) pueden no ver todo el contenido de tu página. Esto puede provocar que no rastreen contenido y enlaces internos importantes para tu web.
- A diferencia de una web con contenido HTML plano, Google rastrea y renderiza una web con Javascript en dos pasos, lo que incrementa el tiempo necesario para su indexación.
Enlazado Interno
Debemos asegurarnos de que el enlazado interno en webs con Javascript se realiza a través de etiquetas html.
???? No uses eventos Javascript como reemplazo de links html. Esto perjudicará a la capacidad de rastreo de los robots.
Identificadores de fragmentos (fragment Identifiers) de URL (# URL)
Webs basadas en Javascript han usado históricamente URLs con identificadores de fragmentos que incluían «#» en su estructura.
Un identificador de fragmento especifica una localización dentro de una misma página.
Esto se suele producir en elementos de la web creados en Javascript con diferentes pestañas. Al hacer click en cada pestaña, la URL cambiará el identificador de fragmento marcado por «#».
Aunque a ojos del usuario, los elementos mostrados en la página son distintos y la URL ha cambiado, Google considera estas variantes como una misma URL. De este modo, URLs con identificadores de fragmento pueden causar problemas de contenido duplicado.
Ejemplo Pestaña 1: www.tusite.com\categoria.html#pestaña1
Ejemplo Pestaña 2: www.tusite.com\categoria.html#pestaña2
URL que tiene en cuenta Google: www.tusite.com\categoria.html
Martin Split explica los dos puntos anteriores en este vídeo de Google Search Central:
Buenas prácticas con Javascript
Si los robots no pueden ver el Javascript de tu página puede ocurrir que rastreen una versión diferente o que se pierdan una parde vital de tu contenido.
- Asegúrate de que los archivos Javascript no son bloqueados en robots.txt
- Asegúrate de que las URLs no incluyen «fragment identifiers» (#)
¿Qué es el server side rendering o renderización del lado del servidor?
Este proceso se utiliza para mitigar el renderizado en dos pasos que hace Google de una página con Javascript y mostrar contenido importante a los buscadores de forma instantánea.
Así es como funciona:
- Se renderiza y se guarda una versión de la página en el servidor.
- Cuando la web recibe una visita, se comprueba el «user agent».
- Si el «user agent» es un robot de un buscador, se mandará al buscador la versión pre renderizada de la página que se guardó anteriormente.
Os dejo aquí dos artículos explicándolo en detalle:
- SEO SEO: Representación del lado del servidor frente a la representación del lado del cliente
- Javascript y SEO: Cómo testear el renderizado de JS
¿Qué es SPA?
SPA es el acrónimo de Single Page Application. Estas son son aplicaciones que Javascript usa para actualizar dinámicamente una página en lugar de cargar nuevas páginas del servidor.
Estas aplicaciones, si no están bien implementadas, pueden causar problemas al SEO de tu página. Desde hace un tiempo, sin embargo, este problema no lo es tanto ya que Google es capaz de entender Javascript mucho mejor.
Pese a todo, no todos los buscadores responden igual que Google a los sitios con Javascript e incluso para Google puede ser dificil en ciertos casos rastrear una web con Javascript.
Si quieres más información al respecto te recomiendo leer:
- Cómo mejorar el posicionamiento SEO de una página web Single Page Application
- ¿Cómo hacer que tu Single Page Applications (SPA) sea indexable por el bot de Google?
¿Qué es el pre-rendering y cómo beneficia al SEO de tu web?
El pre-rendering es el proceso por el cual las páginas son renderizas y cacheadas en el lado el servidor.
La versión en caché de la web será la enviada a los robots de búsqueda mientras que los usuarios verán la versión actual de la web.
Esto puede provocar que las versiones que los robots y los usuarios ven sean distintas. Sin embargo, mientras que la versión cache se actualice de forma regular no debe existir ningún riesgo de penalización ya que las diferencias serán mínimas.
???? Cachear una web es almacenar de forma temporal para que su contenido estático sea accesible de manera frecuente.
Cómo identificar diferencias entre la versión caché y la live de una web
De nuevo Screaming Frog al rescate. Tendremos que hacer 2 rastreos diferentes.
- Crawl usando Javascript rendering y un custom user agent.
- Crawl usando text-only rendering y Googlebot como user agent.
De forma manual, este análisis se puede realizar con extensiones Chrome que permitan cambiar el user agent.
Espero que este artículo te haya sido útil. Googlebot es cada año más capaz de rastrear e indexar contenido en Javascript y la mayoría de problemas de antaño están olvidados. Pese a todo, es bueno conocerlos y evitar que afecten a tu estrategia SEO.
